SpeechOp Demo
SpeechOp: Inference-Time Task Composition for Generative Speech Processing
Justin Lovelace, Rithesh Kumar, Jiaqi Su, Ke Chen, Kilian Q. Weinberger, Zeyu Jin
Paper (arXiv)Abstract
While generative Text-to-Speech (TTS) systems leverage vast "in-the-wild" data to achieve remarkable success, speech-to-speech processing tasks like enhancement face data limitations, which lead data-hungry generative approaches to distort speech content and speaker identity. To bridge this gap, we present SpeechOp, a multi-task latent diffusion model that transforms pre-trained TTS models into a universal speech processor capable of performing a wide range of speech tasks and composing them in novel ways at inference time. By adapting a pre-trained TTS model, SpeechOp inherits a rich understanding of natural speech, accelerating training and improving S2S task quality, while simultaneously enhancing core TTS performance. Finally, we introduce Implicit Task Composition (ITC), a novel pipeline where ASR-derived transcripts (e.g., from Whisper) guide SpeechOp's enhancement via our principled inference-time task composition. ITC achieves state-of-the-art content preservation by robustly combining web-scale speech understanding with SpeechOp's generative capabilities.
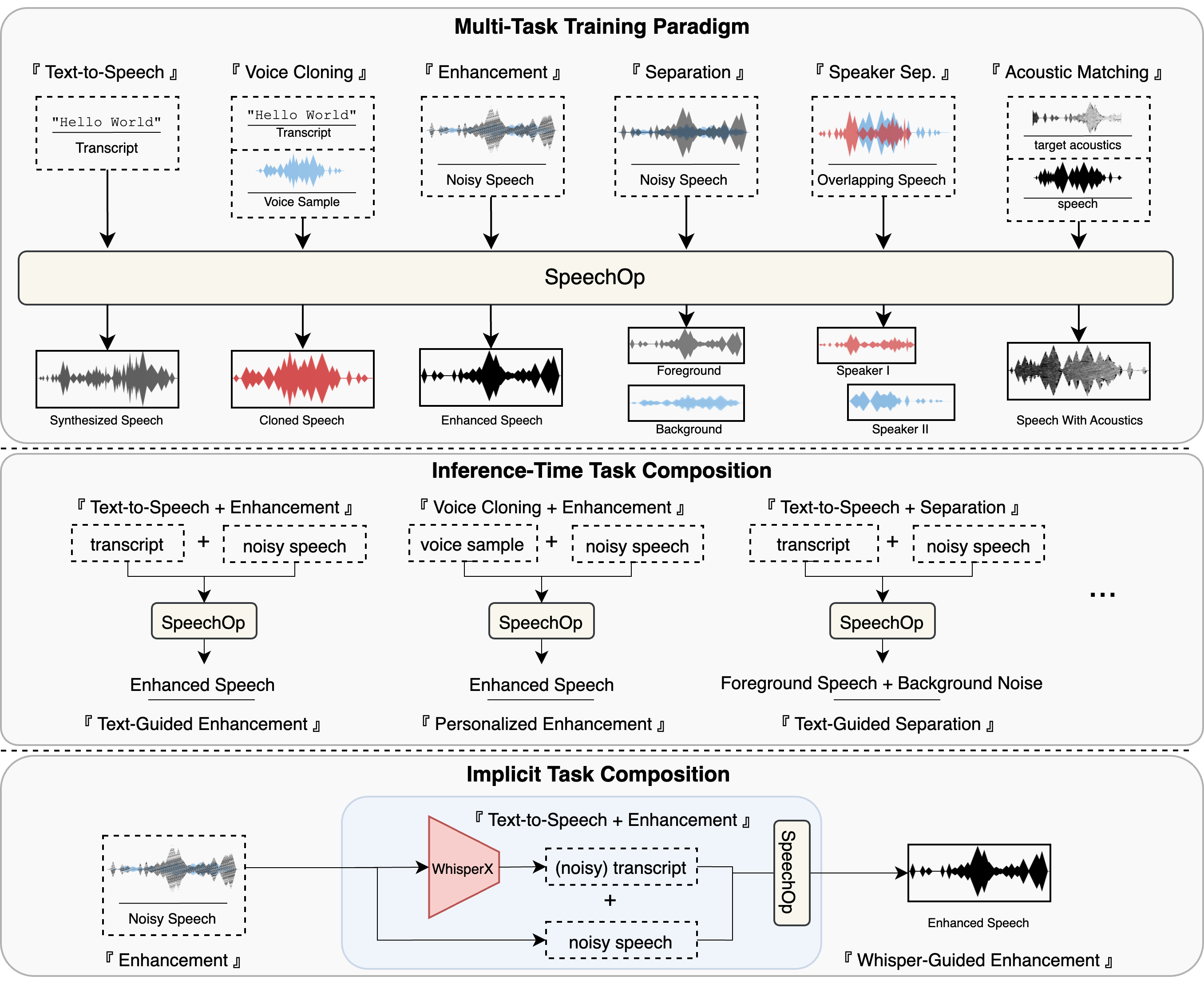
The following examples demonstrate SpeechOp's speech enhancement and foreground/background separation capabilities. Compare the enhancement results with and without TTS guidance (Implicit Task Composition), which uses an ASR-derived transcript to improve content preservation via our TC-CFG inference-time task composition strategy.
Noisy Speech (Example 1)
Enhancement
Foreground / Background Separation
Noisy Speech (Example 2)
Enhancement
Foreground / Background Separation
Reverberant Speech
Enhancement
Foreground Separation
Speaker Separation
SpeechOp separates overlapping speakers from a mixture, using a reference speech sample to identify the target speaker. We show results on LibriMix with both clean and noisy backgrounds, with and without TTS guidance for improved content preservation.
Clean Background
Speaker 0
Speaker 1
Noisy Background
Speaker 0
Speaker 1
Zero-Shot Text-to-Speech
SpeechOp generates speech in a target speaker's voice given only a short speech prompt. Multi-task training on speech processing tasks actually improves TTS quality compared to a TTS-only baseline.
Example 1
Example 2
Speech Editing
SpeechOp edits a specific segment of an utterance while preserving the surrounding speech, maintaining speaker identity and natural prosody across the edit boundary.